香港中文大学一个团队新作登上了Nature,他们用一片小到10平方毫米的超表面芯片,让边缘设备初次获得了"基础模型"级别的视觉解析能力。
光学计算领域长期存在的一个困境
光学神经网络(ONN)的优势被反复强调:传播速度快、天生具备并行特性、能耗低。可实际情况如何?过去十年间,多数ONN实验还仅限于MNIST手写数字和Fashion-MNIST服装识别这类简单任务,参数量普遍停留在几万到几十万级别,与当前人工智能模型动辄数千万甚至千亿参数的规模相比,差距十分明显。
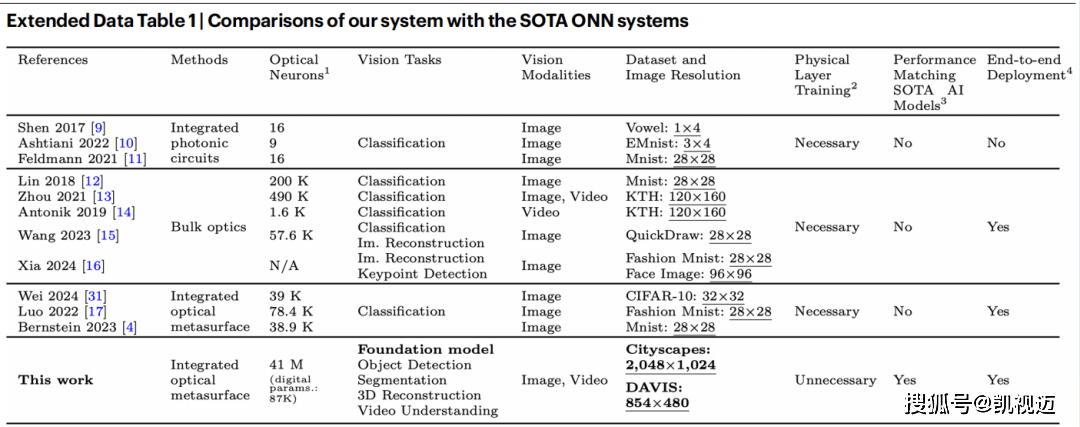
Extended Data Table 1的对比图清晰地展示了这个问题:早前ONN系统要么局限于分类任务,要么需要为不同任务重新设计物理装置,没有任何一个系统能同时胜任检测、分割、三维重建和视频理解这四项任务,水准也远不及当前数字模型的顶尖水平。
症结究竟出在哪里?
ONN研究长期存在一个基本预设——光学子系统应当去精确复制数字神经网络的代数运算。比如光学卷积神经网络试图在物理层面重现卷积核的乘加过程,光学衍射网络则用光场传播模拟全连接层的矩阵乘法。这种"数字模拟"方式在物理实现中代价高昂且误差频出:光学系统根本不适合进行高精度代数运算,一旦强求就会在参数规模、非线性处理和可扩展性等方面全面碰壁。
共同第一作者:Jiayong Peng、Mingcheng Luo
通讯作者:Chaoran Huang
研究机构:
香港中文大学 电子工程系 / 计算机科学与工程系(The Chinese University of Hong Kong, Shatin, Hong Kong)
香港理工大学 应用物理系(Yang Chai组)
Queen's University, Canada(B. J. Shastri组)
合肥综合性国家科学中心 人工智能研究院(Yuxi Han)
港中文黄超然团队在Nature发表的这项工作彻底打破了旧有思维。其核心理念是:不再让光学系统去"模仿"数字模型的运算过程,而是将计算机视觉三大基本原理——基于相似度的识别、注意力引导的感知、细节与上下文的统一处理——直接构建到超表面的物理设计与光传播机制中。
这一理念转换带来的结果是:一个固定不变的4100万参数光学超表面前端,配合仅8.7万参数的极简数字后端,在Cityscapes和DAVIS这类高分辨率真实世界数据集上,于目标检测、语义分割、三维重建和视频理解这四项任务中全面超越了数百万乃至数亿参数的数字模型。
从"精确模拟"到"物理嵌入"的思维革新
这项研究的创新之处在于突破了"用光学系统复制数字网络"的思维局限。在现有文献中,ONN的智能通常体现在如何更精确地实现某种数学变换。但这项研究的研究者们发现,现代计算机视觉的三大支柱——基于相似度的识别、注意力机制的感知、以及细节与上下文的整合——并非只能通过复杂公式实现。他们另辟蹊径,将这些原则直接"物理化"到一块仅有10平方毫米的"光学超表面"上。
图1 | 我们整体系统的工作流程示意图。
这块超表面还融合了注意力机制和多尺度特征提取两大技术。它通过精巧的光学结构设计,让每个输入像素点都由256个不同的纳米柱进行调制,从而产生256个卷积核,这与数字网络中的通道注意力机制别无二致。
同时,通过调节光波衍射距离(d1和d2),系统能自然地提取出局部的"细节特征"和全局的"上下文特征",这恰好是卷积神经网络和Transformer的核心机制,但整个过程都在光通过芯片的瞬间以光速、零功耗完成。
光学"超表面":个参数量达4100万的无源"智慧体"
这个"光学超表面"芯片,其核心是由4100万个按照高斯分布随机排列的硅纳米柱(meta-atoms)构成的巨大阵列。看到这里,